The Structural Evolution of Compute Architectures in the AI Era: CPU, GPU, and TPU — Which U you may need?

In a bustling digital kitchen, dinner service was about to begin.
At the center stood Chef CPU, the calm and experienced master chef. With only a few knives but years of training, CPU read the orders, planned the menu, and told everyone what to do next. Timing, coordination, and precision were CPU’s specialties. Without the master chef, the kitchen would descend into chaos.
Behind the scenes, the heat turned up as the GPU Team sprang into action. Hundreds of cooks moved in perfect rhythm, rolling, frying, and stacking by the thousands. Each cook handled a small task, but together they produced an endless flow of golden at incredible speed. Whenever a massive banquet—or an AI model training—was underway, this team carried the workload.
Then, in a quiet corner, the TPU Dessert Robot hummed to life. It didn’t care about menus or variety. Its only job was to fry flawless spiral dessert, again and again, with almost no wasted oil or energy. For this one task, nothing in the kitchen could match its efficiency. When the orders were predictable and enormous, the robot never slowed down.
As the night went on, the secret of the kitchen became clear: the master chef didn’t compete with the GPU team, and the GPU team didn’t fear the robot. Each had a role. Together, they served millions of plates—fast, efficiently, and without burnout.
And that’s how the modern AI kitchen works:
CPU plans, GPU scales, TPU optimizes.
Artificial Intelligence: A Structural Force in Computing
Artificial intelligence has moved beyond the realm of incremental software innovation and has become a structural force reshaping the global computing industry. Unlike previous technology cycles—such as enterprise software, mobile computing, or early cloud services—modern AI progress is increasingly constrained by physical and economic limits rather than purely algorithmic creativity. The explosive growth of deep learning models, particularly large language models and multimodal systems, has driven unprecedented demand for computation, memory bandwidth, and electrical power.
As a result, the traditional paradigm of homogeneous, CPU-centric computing is no longer sufficient. Instead, the industry is undergoing a structural transition toward heterogeneous compute architectures that combine CPUs, GPUs, and specialized accelerators such as Tensor Processing Units (TPUs). This transition is not a short-term optimization, but a durable response to fundamental constraints imposed by physics, energy availability, and scale economics. For investors, understanding how these architectures differ, how they will evolve, and why they are likely to coexist is essential to evaluating AI infrastructure as a long-duration investment theme.

The Limits of Homogeneous Computing and the Rise of Heterogeneity
For much of the past four decades, computing performance improved through a relatively simple mechanism: faster CPUs enabled more complex software. Advances in semiconductor manufacturing, combined with architectural techniques such as instruction-level parallelism and speculative execution, allowed general-purpose processors to deliver steady performance gains. However, this approach has reached diminishing returns.
AI workloads have accelerated the exposure of these limits. Deep learning relies overwhelmingly on dense numerical computation, particularly matrix multiplications applied repeatedly across large datasets. These workloads exhibit high arithmetic intensity but minimal branching, making them poorly suited to CPUs optimized for control-heavy, irregular execution patterns. Attempting to scale AI purely on CPUs results in low hardware utilization and unsustainable energy consumption.
Heterogeneous computing therefore emerged as a structural necessity rather than a design preference. By allocating different stages of computation to architectures optimized for specific constraints, heterogeneous systems dramatically improve overall efficiency. Modern AI systems increasingly resemble engineered pipelines rather than monolithic processors, reflecting a fundamental shift in how computation is produced and consumed.
CPU: From Primary Compute Engine to System Control Plane
Despite their declining role in raw AI computation, CPUs remain indispensable components of modern systems. Their architectural strengths—flexibility, precise control, and broad compatibility—are uniquely suited to system orchestration tasks that accelerators cannot efficiently perform.
In heterogeneous environments, CPUs manage task scheduling, coordinate data movement between accelerators, handle input/output operations, and ensure overall system stability. As AI workloads grow more complex, these responsibilities become more critical rather than less. Industry roadmaps increasingly emphasize CPU investments in memory bandwidth, interconnects, and coherent fabrics that enable tighter integration with GPUs and custom accelerators.
Looking ahead, CPUs are likely to deepen their role as control-plane processors. Their economic value will be driven less by benchmark leadership and more by platform reliability, ecosystem compatibility, and integration with heterogeneous systems. From an investment perspective, this suggests that CPU-related businesses may exhibit steadier, lower-volatility growth profiles, anchored by entrenched positions in enterprise and cloud infrastructure even as AI accelerators capture incremental compute spending.
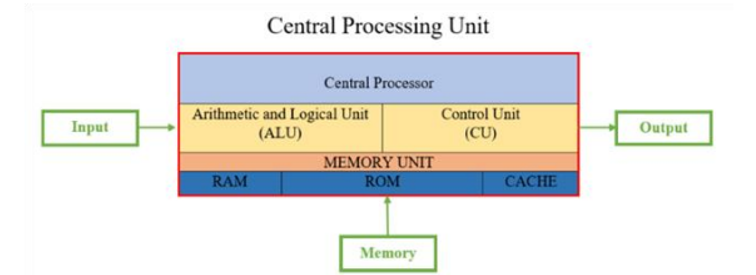
GPU: The Backbone of AI Compute Infrastructure
GPUs occupy the central position in today’s AI compute landscape. Originally designed for graphics rendering, GPUs are architected around massive parallelism, enabling thousands of simple compute cores to execute identical operations simultaneously. This design aligns naturally with the data-parallel structure of deep learning workloads.
What distinguishes GPUs from more specialized accelerators is their balance between throughput and adaptability. GPUs sacrifice some control complexity in exchange for massive arithmetic density, while remaining programmable enough to support evolving algorithms, numerical formats, and training techniques. This flexibility has been reinforced by a mature software ecosystem, particularly CUDA and GPU-optimized AI frameworks, which has created strong network effects and high switching costs.
As AI models continue to scale, GPUs are evolving to address emerging constraints. Recent architectural trends emphasize lower-precision arithmetic, high-bandwidth memory, chiplet-based designs, and increasingly sophisticated interconnects to support large, tightly coupled clusters. These innovations are aimed not at maximizing peak performance, but at sustaining efficiency and scalability under growing energy and communication constraints.
From an investment standpoint, GPUs represent core infrastructure assets rather than cyclical hardware products. Their value derives not only from performance leadership, but from ecosystem dominance, developer dependence, and deep integration into cloud platforms and enterprise workflows.
TPUs and Custom Accelerators: Specialization at Hyperscale
TPUs exemplify a more specialized approach to AI computation. Designed explicitly for tensor operations, TPUs optimize dataflow and minimize memory access through architectural features such as systolic arrays and large on-chip buffers. These design choices enable significantly higher performance per watt for workloads that match TPU assumptions.
The economic logic of TPUs is strongest at hyperscale. Large cloud providers operate under stringent power, cooling, and space constraints, where even incremental efficiency gains can translate into substantial long-term cost savings. Custom accelerators also allow hyperscalers to reduce dependence on third-party hardware and optimize performance for internal workloads.
However, specialization introduces rigidity. TPUs are less flexible than GPUs and depend on stable, predictable workloads to justify their development and deployment costs. As a result, their adoption is concentrated among a small number of hyperscale operators with sufficient scale and engineering resources. For investors, this trend suggests increasing vertical integration and market concentration within AI infrastructure rather than broad-based disruption.
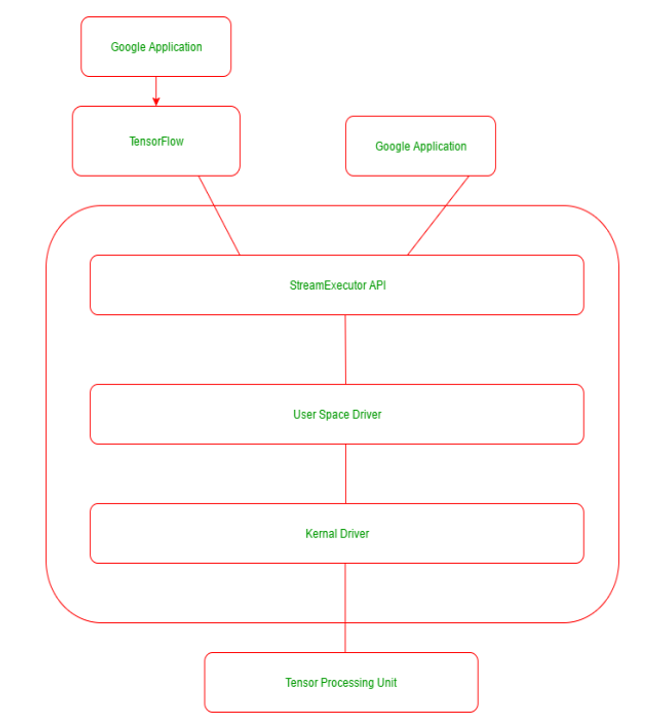
Energy, Power, and the Economics of AI Scaling
Energy consumption has emerged as the dominant constraint on AI scaling. Public disclosures from major cloud providers increasingly highlight power availability and efficiency as limiting factors for future capacity expansion. Rising electricity costs, grid constraints, and sustainability pressures all influence hardware selection and system design.
This reality favors architectures that minimize data movement and operate efficiently at lower numerical precision. GPUs and TPUs have evolved in this direction through different design philosophies, while CPUs play a critical role in power-aware scheduling and system optimization. Over the next decade, improvements in energy efficiency are likely to matter more than increases in peak compute performance.
For investors, this shift implies that competitive advantage in AI infrastructure will increasingly be determined by system-level efficiency rather than isolated component metrics. Platforms that optimize power, cooling, and utilization holistically are likely to outperform those focused solely on raw performance.
As compute efficiency improves, bottlenecks are shifting toward memory bandwidth, interconnect latency, and packaging technologies. High-bandwidth memory, advanced chiplet architectures, and increasingly complex interconnect fabrics are becoming central to AI system performance.
Industry research consistently shows that reducing data movement yields greater efficiency gains than increasing compute density alone. This insight has driven investment in 2.5D and 3D packaging, optical interconnects, and processing-near-memory concepts. These developments blur the boundary between compute and system design, reinforcing the importance of integration capabilities.
From an investment perspective, this trend broadens the opportunity set within AI infrastructure, extending value creation beyond compute cores to memory suppliers, interconnect providers, and advanced packaging technologies.
Training and inference impose fundamentally different demands on compute systems. Training workloads are experimental, iterative, and dynamic, favoring flexible platforms such as GPUs. Inference workloads, by contrast, prioritize efficiency, predictability, and cost minimization.
As AI applications scale to consumer and enterprise deployment, inference is expected to dominate total compute consumption. This shift has significant implications for architecture demand, increasing the relevance of specialized accelerators optimized for energy-efficient inference. Over time, inference-focused hardware may capture a growing share of AI infrastructure spending, even as training remains strategically important for innovation.
The notion that one architecture will ultimately replace the others oversimplifies the economics of modern compute systems. CPUs, GPUs, and TPUs optimize for different constraints and therefore occupy distinct positions within the compute stack. Attempts to force one architecture into another’s role typically result in inefficiency rather than competitive displacement.
Instead, the industry is converging toward a layered equilibrium in which heterogeneous architectures coexist. This coexistence reflects rational optimization under physical, economic, and operational constraints and is likely to persist as AI workloads diversify rather than converge.

Long-Term Investment Outlook: AI Compute as Infrastructure (AI infrastructure landscape)
From an investment standpoint, AI compute should be viewed with high conviction as a multi-decade infrastructure theme rather than a cyclical hardware market. Cumulative global spending on AI-related compute, data centers, and power infrastructure is widely estimated to reach USD 1–1.5 trillion by 2030, driven primarily by hyperscale cloud providers and large enterprises. Even at peak build-out, annual AI infrastructure investment is expected to remain below 1% of global GDP, consistent with historical infrastructure cycles such as cloud data centers and telecom networks. Demand dynamics appear fundamentally structural: while algorithmic and hardware efficiency has improved at an estimated 30–40% per year, total AI compute consumption has been growing at 60–80%+ annually, implying a persistent supply–demand gap that must be met through continued infrastructure investment.
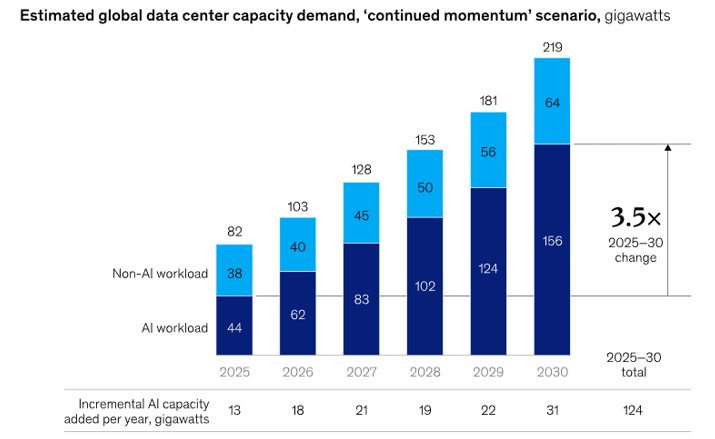
Within the AI infrastructure landscape, value creation is increasingly distributed across interdependent layers rather than isolated components. At the base layer, power generation, grid access, and data center real estate are emerging as binding constraints, with AI workloads consuming 2–5× more power per rack than traditional cloud workloads. Above this, compute hardware—spanning CPUs for system orchestration, GPUs for flexible parallel computation, and custom accelerators such as TPUs for energy-efficient inference—forms the core execution layer. Networking and interconnect technologies, including high-speed fabrics and advanced packaging, are becoming equally critical as model scale drives communication overhead. At the system and software layer, scheduling, compilers, and AI frameworks increasingly determine utilization rates and total cost of ownership, reinforcing the importance of vertical integration.
Inference is expected to be the dominant long-term demand driver. Industry forecasts consistently project that 70–80% of total AI compute demand by the end of the decade will come from inference rather than training, transforming AI compute into a recurring, utility-like cost base embedded across consumer, enterprise, and public-sector applications. This shift materially strengthens the infrastructure thesis: inference demand is continuous, geographically distributed, and tightly coupled to end-user services, making it less discretionary and more resilient across economic cycles.
In this landscape, investment outcomes are likely to be highly skewed toward platform-level winners. Durable value is most likely to accrue to ecosystems that integrate hardware, software, networking, power, and system design into cohesive platforms, enabling superior utilization, scalability, and cost efficiency at scale. Isolated component advantages—whether in CPUs, GPUs, or custom accelerators—risk erosion without ecosystem lock-in, developer adoption, and deployment scale. The evolution of compute architectures in the AI era is therefore characterized by differentiation rather than convergence: CPUs, GPUs, and TPUs are not substitutes, but complementary components within heterogeneous systems optimized for distinct physical, economic, and operational constraints. This coexistence represents a structurally stable equilibrium, not a transitional phase.
As artificial intelligence continues to reshape productivity, labor, and capital allocation across the global economy, heterogeneous compute architectures are likely to remain foundational digital infrastructure, comparable in strategic importance to cloud computing or electricity in earlier eras. For long-term investors, this supports a clear conviction: while short-term valuation cycles, capacity overbuilds, and technology shifts are inevitable, exposure to well-positioned AI infrastructure platforms represents a strategic allocation to durable, compounding demand, anchored in system-level scale and integration rather than any single chip generation or architectural winner.
