AI 炒股 = 穩賺?

想像這樣一個場景:你把十年的市場數據輸入一個 AI 模型,按下 Enter,螢幕上立刻生成了一個看似完美的投資組合——年化收益率 32%,最大回撤低於 5%。你的心跳開始加快。你以為自己已經破解了市場。
但那只是一次回測。六個月後,你把同一個模型用於真實市場交易,帳戶卻虧損了 18%。
這樣的情形不僅發生在交易室,也正在世界各地的普通投資者家中上演。過去兩年,AI 驅動投資的想像空間幾乎無法被忽視——把財報數據輸入 GPT,獲得交易想法;用大型語言模型預測宏觀趨勢;看到某量化基金聲稱接入 AI 後實現 40% 的年化收益。這些故事很有吸引力,流向這些故事的資金同樣可觀。
然而,在熱情之下,三層約束正在悄然形成:技術本身的局限、市場競爭的邏輯,以及現實執行中的頑固摩擦。AI 是否能夠穩定地為投資者賺錢,遠比任何回測結果所暗示的都要複雜。

一、AI 投資神話:從何而來?
自 ChatGPT 於 2023 年進入大眾視野以來,一股 AI 投資神話席捲了財經媒體、社交平台,有時甚至也影響到傳統機構。這個敘事大致如下:把財務報表輸入 GPT,就能得到可操作的交易建議;用大型語言模型分析宏觀指標,獲得遠超傳統策略的回報;某量化基金採用 AI 後實現 40% 的年化收益。
這些說法很誘人。但如果追溯其來源,往往會發現一個共同點:它們大多建立在回測、小規模實驗,或與真實世界相距甚遠的理想條件之上。
1.1 回測陷阱
回測,即用歷史數據評估某一策略在過去是否有效,是量化投資的基石。但它有一個根本缺陷:回測是在事後視角下完成的。當研究人員用五年的市場數據訓練一個 AI 模型,並宣布其回測年化收益率達到 30% 時,這個數字並不能說明該策略未來會有怎樣的表現。
回測無法複製真實市場中的摩擦:交易滑點、流動性不足、市場衝擊成本,以及最關鍵的——當策略被廣泛採用後,任何優勢都會被逐步侵蝕。
1.2 小規模幻覺
另一類常見的「成功故事」來自小規模實驗。以 Minotaur Capital 為例,這是一家總部位於雪梨、管理規模約 6,000 萬澳元的基金,且沒有一名人類分析師。其專有 AI 系統 Taurient 每天掃描約 5,000 篇新聞文章。截至 2025 年 1 月的六個月中,該基金回報率為 13.7%,跑贏 MSCI 全球所有國家指數 6.7% 的漲幅——這一結果獲得了彭博社報導,並引發了相當多的關注。
但真正的規模化考驗尚未到來。當資本規模從數千萬增長到數十億時,市場衝擊、流動性約束和執行成本會重塑策略的實際收益,而這些是小規模結果無法預測的。一個策略在小資金規模下有效,到了機構級規模時往往會變得面目全非。
1.3 理想條件謬誤
大多數 AI 投資策略都是在有利條件下展示的:乾淨的數據、充足的流動性、穩定的市場結構,以及沒有重大外部衝擊。真實投資並不提供這些保證。市場嘈雜,數據存在缺口,黑天鵝事件也不會提前通知。2020 年的新冠疫情、2022 年俄羅斯入侵烏克蘭、2025 年的關稅衝擊——這些都不是 AI 模型被充分訓練過的情境。但恰恰是在這些時刻,投資判斷才最重要。

二、第一層約束:技術自身的局限
剝去炒作之後,問題變得很直接:以目前的發展水平,AI 能否持續做出可靠的投資決策?答案是否定的。原因主要有三點。
2.1 幻覺
大型語言模型容易產生「幻覺」——生成聽起來權威、但事實上錯誤的內容。在日常對話中,這只是一個不便;在投資決策中,一個虛構的盈利數字,或對監管規則的錯誤描述,都可能造成嚴重損害。
這些風險並非假設。2024 年,美國證券交易委員會(SEC)對兩家投資顧問公司 Delphia 和 Global Predictions 處以罰款,原因是它們對 AI 在投資流程中的使用方式作出了誤導性陳述。學術研究發現,通用大型語言模型在金融相關問題上的幻覺率最高可達 41%。在高壓、快速變化的投資管理領域,這樣的錯誤率會帶來真實後果。
更深層的問題是不可解釋性。AI 模型很少能以經得起審查的方式解釋自己的推理過程。對於需要向投資委員會、客戶和監管機構解釋決策的機構投資者而言,缺乏可解釋性並不是一個小的技術缺陷,而是一項實質性風險。
2.2 數據不可靠
AI 模型的可靠性取決於其所使用的數據。在投資領域,數據問題尤其突出。
首先是時滯。大多數大型語言模型都有訓練截止日期。市場即時變化,而模型知識並不會同步更新。即便 AI 系統接入了即時數據流,也仍然需要面對數據品質、標準化不一致和解讀偏差等問題。
其次是另類數據。近年來,投資機構越來越多地使用所謂另類數據——例如透過衛星影像追蹤停車場車流以推斷零售銷售情況,透過信用卡交易數據判斷消費趨勢,透過社交媒體情緒預測價格變動。由於這些數據集位於傳統金融數據體系之外,理論上可以提供資訊優勢。但在實踐中,數據品質參差不齊,而且任何特定信號與市場回報之間的關係都會隨時間變化。當越來越多投資者追逐同一類數據源時,稀缺優勢就會變成公共資訊,而公共資訊無法創造 alpha。
第三是非平穩性。金融數據不同於影像識別或通用自然語言處理中的輸入數據。市場統計特徵並不穩定;它們會隨著政策、流動性和投資者結構的變化而變化。某個在一個市場環境中有效的模式,可能在另一個環境中完全失效。這使得泛化能力——即在新環境中保持可靠表現的能力——在金融 AI 中遠比多數其他應用更難實現。
2.3 預測的邊界
也許最深層的限制在於:無論 AI 變得多麼強大,它本質上仍是一種模式識別工具。它可以識別歷史數據中的關係,但無法擺脫過去經驗的邊界。
市場不是靜態系統。市場由數以百萬計的人類決策共同塑造,而這些決策又受到預期影響,預期本身則會對價格變動作出反應。這種反饋循環意味著市場模式會不斷修正並瓦解自身。一旦某個由 AI 識別出的模式被廣泛跟隨,該模式就會消失——被它自身引發的行為所侵蝕。策略越成功,它播下自身失效種子的速度就越快。

三、第二層約束:市場競爭的邏輯
假設 AI 能夠在某一策略中產生超額收益。接下來會發生什麼?
3.1 Alpha 是競爭優勢,而優勢會衰減
在金融市場中,alpha 指的是超過基準的收益——通俗地說,是因為比市場更聰明或更快而獲得的獎勵。AI 策略本質上是使用機器學習模型或大型語言模型來分析數據、生成信號,並輔助或替代人類投資判斷。當某人能夠比其他人更快或更準確地識別並利用資訊優勢時,alpha 就會存在,無論這種優勢來自人類分析還是機器智慧。
但市場競爭極其激烈。一旦某個策略被證明有效,資本和人才就會湧入,直到超額收益消失。這一動態同樣適用於 AI 策略,而且在某些方面更為嚴酷。AI 策略傳播速度快,也相對容易被複製。從發現一個有效信號到它被廣泛複製,這個窗口可能只有幾個月,甚至幾週。
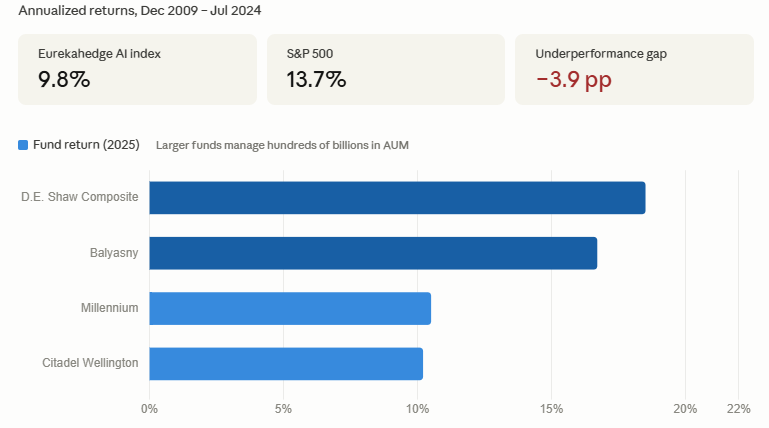
長期證據並不樂觀。Eurekahedge AI Hedge Fund Index 在 2009 年 12 月至 2024 年 7 月期間的年化收益率為 9.8%。同期,標普 500 指數的年化收益率為 13.7%。在長達 15 年的周期中,AI 主題對沖基金作為一個類別並未跑贏市場,反而落後於市場。早期參與者或許曾獲得優勢,但隨著策略擴散,這種優勢逐漸消退。
3.2 規模悖論
即使某個 AI 策略在小規模下確實有效,擴大規模通常也會引入一種結構性約束,削弱原本的優勢。
反直覺的現實是:策略管理的資金規模越大,執行就越困難。當一個策略控制足夠多資金時,它會開始影響自己試圖交易的資產價格——買入會推高價格,賣出會壓低價格。策略最終會變成自己的對手。
這解釋了為什麼許多在有限實驗中表現亮眼的 AI 策略,難以在機構級規模下複製同樣結果。2025 年對沖基金業績數據提供了一個有用參照:D.E. Shaw 的 Composite Fund 上漲約 18.5%;Balyasny 回報約 16.7%;Citadel 旗艦基金 Wellington 上漲約 10.2%;Millennium 上漲約 10.5%。規模與收益並不總是同向變化。在 AI 時代,alpha 更依賴靈活性、精確性和時機,而不僅僅是模型複雜度。最好的 AI 並不總能帶來最好的回報。
四、第三層約束:現實執行的摩擦
為了論證方便,假設某個 AI 系統確實具備預測能力,而且市場尚未完全吸收其信號。此時還有一個更重要、卻往往被低估的問題:這些能力能否在真實投資機構中被可靠執行?
投資並不是一個模型給出答案、資金就自動跟隨的過程。真實投資決策要經過研究、風險管理、交易、合規和客戶溝通等環節,每一步都可能引入摩擦。AI 的優勢在於速度、數據處理和自動化。而機構投資管理的核心要求則是審慎、可解釋和可問責。這兩組要求並不天然一致。
4.1 人機衝突
在多數投資機構中,AI 是工具,而不是決策者。最終投資決策仍由人來作出。
這會產生結構性張力。當 AI 信號與基金經理判斷衝突時,誰說了算?如果模型建議買入,而基金經理認為風險太高,信號就會被忽略。如果模型建議減倉,而基金經理擔心錯過上漲,模型就會被推翻。長期來看,AI 策略在真實環境中的執行結果,並不完全反映模型輸出,而是機器信號與人類直覺反覆妥協後的結果。
這也是許多 AI 策略在回測中表現出色、但在實盤中令人失望的原因。問題往往不在於模型錯誤,而在於模型從未被持續一致地執行。
4.2 機構流程稀釋 AI 的速度優勢
速度是 AI 最常被提及的優勢之一。它可以處理海量資訊、識別市場變化,並以遠快於任何人類團隊的速度生成交易信號。
但大型投資機構並不是為極致速度而設計的。從模型信號到實際下單,通常需要經過風險管理審批、倉位限制檢查、投資委員會討論、合規審查,有時還需要客戶授權。這些流程有其合理性——它們保護投資者,並防止模型失控運行。但它們也會削弱 AI 最被依賴的優勢。
當一個信號必須經過多層審批才能執行時,價格可能已經變動,機會可能已經消失。AI 提供的是即時判斷,而機構基礎設施往往帶有延遲。兩者之間的差距足以抹去本就微薄的 alpha。
4.3 當模型失效時,你可能不知道原因
還有一種執行風險常常未被充分重視:當 AI 策略開始失效時,這種失效可能難以發現,更難診斷。
當傳統策略表現惡化時,基金經理通常可以追溯其邏輯。是宏觀判斷錯誤?還是行業判斷失誤?但在 AI 策略中,決策過程往往不透明。當收益開始下降時,人們可能無法判斷究竟是市場環境發生了變化,還是模型對歷史模式過度擬合,抑或底層數據品質出現惡化。這種不透明性使風險管理和退出決策比傳統策略困難得多。
結果是:執行 AI 策略不僅要問你能否遵循信號,還要問你什麼時候應該停止信任模型。後一個問題很少有清晰答案。

五、三重約束對投資者意味著什麼?
技術、市場和執行三個維度結合起來,能更完整地回答 AI 是否能夠可靠地為投資者賺錢這一問題。
從技術層面看,AI 仍然不穩定。幻覺、不可靠數據,以及對真正新事件的有限預判能力,意味著 AI 還無法持續作出穩健、獨立的投資決策。它可以作為人類判斷的有用補充,但遠未成為可靠的自主決策者。
從結構層面看,AI 驅動的優勢難以維持。即使 AI 在某一時點創造了 alpha,市場競爭也往往會迅速侵蝕這種優勢。策略複製速度比以往更快,而規模悖論限制了即便有效的策略能夠擴展到多大程度。
從操作層面看,執行遠比看起來更困難。即便模型按預期運行,機器信號與機構流程之間的摩擦,再加上 AI 決策過程的不透明,通常會使實盤收益顯著低於回測所暗示的水平。
由此可以得出三個實踐結論。
第一,不要高估 AI 創造收益的能力。大多數被廣泛引用的 AI 投資成功案例,都依賴回測、有利市場條件或小規模實驗,既不可持續,也難以複製。在評估 AI 驅動產品時,應要求查看實盤業績記錄,並要求對 AI 實際如何參與投資流程作出清晰說明。
第二,AI 是工具,不是策略。它最有防禦性的角色,是提高投資流程效率——降低研究成本、加快資訊處理、支持風險識別、減少營運開支。最有效的應用往往是協作型應用:AI 負責數據密集型分析,人類保留最終決策權。
第三,執行能力與模型品質同樣重要。一個強大的 AI 信號,如果不能被持續一致地執行,也不會產生強勁回報。在評估任何 AI 驅動投資方法時,正確的問題不只是「模型有多好?」,還應包括「這個機構是否具備可靠執行該模型的紀律和基礎設施?」

六、結論
回到文章開頭的辦公室場景。螢幕上的回測數字依舊亮眼——年化收益率 32%,最大回撤低於 5%。但這些數字背後,隱藏著三層回測無法展示的現實。
從技術上看,模型會產生幻覺,數據會誤導人,黑天鵝事件也不在任何訓練集之內。從結構上看,有效信號會被迅速複製,alpha 窗口關閉的速度比表面看起來更快。從操作上看,人類判斷與機器輸出之間的摩擦、機構流程中的延遲,以及模型開始失效時的沉默,都會共同拉大理論表現與實際收益之間的差距。
AI 不是市場的秘密代碼。它是一種工具——真實存在、不斷演進,並且在合適情境下確實有用。但工具終究只是工具。它不能替代判斷,不能消除不確定性,也不能保證收益。
最持久的投資優勢,從來不是來自擁有最複雜的工具,而是來自清楚、誠實地理解這個工具能做什麼、不能做什麼。在 AI 時代,這種清醒認知,正是穩健投資決策的起點。
